Coding the forward propagation algorithm¶
In [ ]:
import numpy as np
In [ ]:
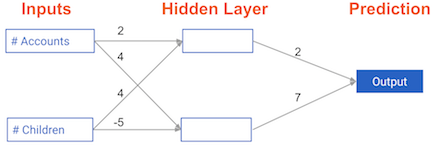
weights = { 'node_0': np.array([2,4]),
'node_1': np.array([4, -5]),
'output': np.array([2,7])}
input_data = np.array([3,5])
# Calculate node 0 value: node_0_value
node_0_value = (weights['node_0'] * input_data).sum()
# Calculate node 1 value: node_1_value
node_1_value = (weights['node_1'] * input_data).sum()
# Put node values into array: hidden_layer_outputs
hidden_layer_outputs = np.array([node_0_value, node_1_value])
# Calculate output: output
output = (weights['output'] * hidden_layer_outputs).sum()
# Print output
print(output)
The Rectified Linear Activation Function¶
In [ ]:
def relu(input):
'''Define your relu activation function here'''
# Calculate the value for the output of the relu function: output
output = max(input, 0)
# Return the value just calculated
return(output)
# Calculate node 0 value: node_0_output
node_0_input = (input_data * weights['node_0']).sum()
node_0_output = relu(node_0_input)
# Calculate node 1 value: node_1_output
node_1_input = (input_data * weights['node_1']).sum()
node_1_output = relu(node_1_input)
# Put node values into array: hidden_layer_outputs
hidden_layer_outputs = np.array([node_0_output, node_1_output])
# Calculate model output (do not apply relu)
model_output = (hidden_layer_outputs * weights['output']).sum()
# Print model output
print(model_output)
In [ ]:
relu(3)
In [ ]:
relu(-1)
In [ ]:
# Define predict_with_network()
def predict_with_network(input_data_row, weights):
# Calculate node 0 value
node_0_input = (input_data_row * weights['node_0']).sum()
node_0_output = relu(node_0_input)
# Calculate node 1 value
node_1_input = (input_data_row * weights['node_1']).sum()
node_1_output = relu(node_1_input)
# Put node values into array: hidden_layer_outputs
hidden_layer_outputs = np.array([node_0_output, node_1_output])
# Calculate model output
input_to_final_layer = (hidden_layer_outputs * weights['output']).sum()
model_output = relu(input_to_final_layer)
# Return model output
return(model_output)
In [ ]:
weights = {'node_0': np.array([2, 4]), 'node_1': np.array([ 4, -5]), 'output': np.array([2, 7])}
input_data = [np.array([3, 5]), np.array([ 1, -1]), np.array([0, 0]), np.array([8, 4])]
# Create empty list to store prediction results
results = []
for input_data_row in input_data:
# Append prediction to results
results.append(predict_with_network(input_data_row, weights))
# Print results
print(results)
Multi-layer neural networks¶
In [ ]:
weights = {'node_0_0': np.array([2, 4]),
'node_0_1': np.array([ 4, -5]),
'node_1_0': np.array([-1, 2]),
'node_1_1': np.array([1, 2]),
'output': np.array([2, 7])}
input_data = np.array([3, 5])
def predict_with_network(input_data):
# Calculate node 0 in the first hidden layer
node_0_0_input = (input_data * weights['node_0_0']).sum()
node_0_0_output = relu(node_0_0_input)
# Calculate node 1 in the first hidden layer
node_0_1_input = (input_data * weights['node_0_1']).sum()
node_0_1_output = relu(node_0_1_input)
# Put node values into array: hidden_0_outputs
hidden_0_outputs = np.array([node_0_0_output, node_0_1_output])
# Calculate node 0 in the second hidden layer
node_1_0_input = (hidden_0_outputs * weights['node_1_0']).sum()
node_1_0_output = relu(node_1_0_input)
# Calculate node 1 in the second hidden layer
node_1_1_input = (hidden_0_outputs * weights['node_1_1']).sum()
node_1_1_output = relu(node_1_1_input)
# Put node values into array: hidden_1_outputs
hidden_1_outputs = np.array([node_1_0_output, node_1_1_output])
# Calculate model output: model_output
model_output = (hidden_1_outputs * weights['output']).sum()
# Return model_output
return(model_output)
In [ ]:
output = predict_with_network(input_data)
output
Q: Which layers of a model capture more complex or "higher level" interactions?
The last layers capture the most complex interactions.
Coding how weight changes affect accuracy¶
In [ ]:
def predict_with_network(input_data, weights):
# Calculate node 0 in the first hidden layer
node_0_0_input = (input_data * weights['node_0']).sum()
node_0_0_output = relu(node_0_0_input)
# Calculate node 1 in the first hidden layer
node_0_1_input = (input_data * weights['node_1']).sum()
node_0_1_output = relu(node_0_1_input)
# Put node values into array: hidden_0_outputs
hidden_0_outputs = np.array([node_0_0_output, node_0_1_output])
# Calculate model output: model_output
model_output = (hidden_0_outputs * weights['output']).sum()
# Return model_output
return(model_output)
In [ ]:
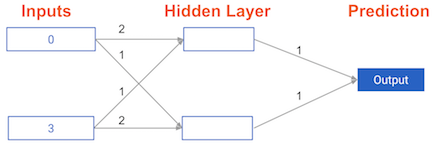
# The data point you will make a prediction for
input_data = np.array([0, 3])
# Sample weights
weights_0 = {'node_0': [2, 1],
'node_1': [1, 2],
'output': [1, 1]
}
# The actual target value, used to calculate the error
target_actual = 3
# Make prediction using original weights
model_output_0 = predict_with_network(input_data, weights_0)
# Calculate error: error_0
error_0 = model_output_0 - target_actual
# Create weights that cause the network to make perfect prediction (3): weights_1
weights_1 = {'node_0': [2, 1],
# changed node_1 weight as [1,0]
'node_1': [1, 0],
'output': [1,1]
}
# Make prediction using new weights: model_output_1
model_output_1 = predict_with_network(input_data, weights_1)
# Calculate error: error_1
error_1 = model_output_1 - target_actual
# Print error_0 and error_1
print(error_0)
print(error_1)
Scaling up to multiple data points¶
In [ ]:
input_data = [np.array([0, 3]), np.array([1, 2]), np.array([-1, -2]), np.array([4, 0])]
target_actuals = [1, 3, 5, 7]
weights_0 ={'node_0': np.array([2, 1]), 'node_1': np.array([1, 2]), 'output': np.array([1, 1])}
weights_1 = {'node_0': np.array([2, 1]), 'node_1': np.array([1. , 1.5]), 'output': np.array([1. , 1.5])}
In [ ]:
from sklearn.metrics import mean_squared_error
# Create model_output_0
model_output_0 = []
# Create model_output_0
model_output_1 = []
# Loop over input_data
for row in input_data:
# Append prediction to model_output_0
model_output_0.append(predict_with_network(row, weights_0))
# Append prediction to model_output_1
model_output_1.append(predict_with_network(row, weights_1))
# Calculate the mean squared error for model_output_0: mse_0
mse_0 = mean_squared_error(target_actuals, model_output_0)
# Calculate the mean squared error for model_output_1: mse_1
mse_1 = mean_squared_error(target_actuals, model_output_1)
# Print mse_0 and mse_1
print("Mean squared error with weights_0: %f" %mse_0)
print("Mean squared error with weights_1: %f" %mse_1)
In [ ]:
model_output_0
In [ ]:
model_output_1
Calculating slopes¶
When plotting the mean-squared error loss function against predictions, the slope is 2 * x * (y-xb), or 2 * input_data * error.
In [ ]:
input_data = np.array([1, 2, 3])
weights = np.array([0, 2, 1])
target = 0
In [ ]:
# Calculate the predictions: preds
preds = (weights * input_data).sum()
# Calculate the error: error
error = preds - target
# Calculate the slope: slope
slope = 2 * input_data * error
# Print the slope
print(slope)
You've just calculated the slopes you need. Now it's time to use those slopes to improve your model.
Improving model weights¶
In [ ]:
# Set the learning rate: learning_rate
learning_rate = 0.01
# Calculate the predictions: preds
preds = (weights * input_data).sum()
# Calculate the error: error
error = preds - target
# Calculate the slope: slope
slope = 2 * input_data * error
# Update the weights: weights_updated
weights_updated = weights - ( learning_rate * slope)
# Get updated predictions: preds_updated
preds_updated = (weights_updated * input_data).sum()
# Calculate updated error: error_updated
error_updated = preds_updated - target
# Print the original error
print(error)
# Print the updated error
print(error_updated)
Making multiple updates to weights¶
In [ ]:
import matplotlib.pyplot as plt
In [ ]:
input_data = np.array([1, 2, 3])
weights = np.array([-0.49929916, 1.00140168, -0.49789747])
target = 0
In [ ]:
def get_slope(input_data, target, weights):
# Calculate the predictions: preds
preds = (weights * input_data).sum()
# Calculate the error: error
error = preds - target
# Calculate the slope: slope
slope = 2 * input_data * error
return slope
In [ ]:
def get_mse(input_data, target, weights_updated):
# Get updated predictions: preds_updated
preds_updated = (weights_updated * input_data).sum()
# Calculate updated error: error_updated
error_updated = preds_updated - target
return error_updated
In [ ]:
n_updates = 20
mse_hist = []
# Iterate over the number of updates
for i in range(n_updates):
# Calculate the slope: slope
slope = get_slope(input_data, target, weights)
# Update the weights: weights
weights = weights - 0.01 * slope
# Calculate mse with new weights: mse
mse = get_mse(input_data, target, weights)
# Append the mse to mse_hist
mse_hist.append(mse)
# Plot the mse history
plt.plot(mse_hist)
plt.xlabel('Iterations')
plt.ylabel('Mean Squared Error')
plt.show()
Creating a keras model¶
In [ ]:
# Import necessary modules
import pandas as pd
import keras
from keras.layers import Dense
from keras.models import Sequential
# Save the number of columns in predictors: n_cols
df = pd.read_csv('../input/hourly-wages/hourly_wages.csv')
#print(df.head())
predictors = df.drop(columns=['wage_per_hour'], axis=1).values
target = df['wage_per_hour'].values
n_cols = predictors.shape[1]
# Set up the model: model
model = Sequential()
# Add the first layer
model.add(Dense(50, activation='relu', input_shape=(n_cols,)))
# Add the second layer
model.add(Dense(32, activation='relu'))
# Add the output layer
model.add(Dense(1))
Compiling and fitting a model¶
In [ ]:
# Compile the model
model.compile(optimizer='adam', loss='mean_squared_error')
# Verify that model contains information from compiling
print("Loss function: " + model.loss)
In [ ]:
# Fit the model
model.fit(predictors, target)
In [ ]:
# Import necessary modules
import pandas as pd
import keras
from keras.layers import Dense
from keras.models import Sequential
from keras.utils import to_categorical
df = pd.read_csv('../input/titanic/titanic_all_numeric.csv')
print(df.head())
predictors = df.drop(columns=['survived'], axis=1).values
#target = df['wage_per_hour'].values
n_cols = predictors.shape[1]
# Convert the target to categorical: target
target = to_categorical(df.survived)
# Set up the model
model = Sequential()
# Add the first layer
model.add(Dense(32, activation='relu', input_shape=(n_cols,)))
# Add the output layer
model.add(Dense(2, activation='softmax'))
# Compile the model
model.compile(optimizer='sgd', loss='categorical_crossentropy', metrics=['accuracy'])
# Fit the model
model.fit(predictors, target)
Making Predictions¶
In [ ]:
# Specify, compile, and fit the model
# Convert the target to categorical: target
#target = df['survived']
pred_data = np.array([[2,34.0,0,0,13.0,1,False,0,0,1] , [2,31.0,1,1,26.25,0,False,0,0,1] , [1,11.0,1,2,120.0,1,False,0,0,1] , [3,0.42,0,1,8.5167,1,False,1,0,0] , [3,27.0,0,0,6.975,1,False,0,0,1] , [3,31.0,0,0,7.775,1,False,0,0,1] , [1,39.0,0,0,0.0,1,False,0,0,1] , [3,18.0,0,0,7.775,0,False,0,0,1] , [2,39.0,0,0,13.0,1,False,0,0,1] , [1,33.0,1,0,53.1,0,False,0,0,1] , [3,26.0,0,0,7.8875,1,False,0,0,1] , [3,39.0,0,0,24.15,1,False,0,0,1] , [2,35.0,0,0,10.5,1,False,0,0,1] , [3,6.0,4,2,31.275,0,False,0,0,1] , [3,30.5,0,0,8.05,1,False,0,0,1] , [1,29.69911764705882,0,0,0.0,1,True,0,0,1] , [3,23.0,0,0,7.925,0,False,0,0,1] , [2,31.0,1,1,37.0042,1,False,1,0,0] , [3,43.0,0,0,6.45,1,False,0,0,1] , [3,10.0,3,2,27.9,1,False,0,0,1] , [1,52.0,1,1,93.5,0,False,0,0,1] , [3,27.0,0,0,8.6625,1,False,0,0,1] , [1,38.0,0,0,0.0,1,False,0,0,1] , [3,27.0,0,1,12.475,0,False,0,0,1] , [3,2.0,4,1,39.6875,1,False,0,0,1] , [3,29.69911764705882,0,0,6.95,1,True,0,1,0] , [3,29.69911764705882,0,0,56.4958,1,True,0,0,1] , [2,1.0,0,2,37.0042,1,False,1,0,0] , [3,29.69911764705882,0,0,7.75,1,True,0,1,0] , [1,62.0,0,0,80.0,0,False,0,0,0] , [3,15.0,1,0,14.4542,0,False,1,0,0] , [2,0.83,1,1,18.75,1,False,0,0,1] , [3,29.69911764705882,0,0,7.2292,1,True,1,0,0] , [3,23.0,0,0,7.8542,1,False,0,0,1] , [3,18.0,0,0,8.3,1,False,0,0,1] , [1,39.0,1,1,83.1583,0,False,1,0,0] , [3,21.0,0,0,8.6625,1,False,0,0,1] , [3,29.69911764705882,0,0,8.05,1,True,0,0,1] , [3,32.0,0,0,56.4958,1,False,0,0,1] , [1,29.69911764705882,0,0,29.7,1,True,1,0,0] , [3,20.0,0,0,7.925,1,False,0,0,1] , [2,16.0,0,0,10.5,1,False,0,0,1] , [1,30.0,0,0,31.0,0,False,1,0,0] , [3,34.5,0,0,6.4375,1,False,1,0,0] , [3,17.0,0,0,8.6625,1,False,0,0,1] , [3,42.0,0,0,7.55,1,False,0,0,1] , [3,29.69911764705882,8,2,69.55,1,True,0,0,1] , [3,35.0,0,0,7.8958,1,False,1,0,0] , [2,28.0,0,1,33.0,1,False,0,0,1] , [1,29.69911764705882,1,0,89.1042,0,True,1,0,0] , [3,4.0,4,2,31.275,1,False,0,0,1] , [3,74.0,0,0,7.775,1,False,0,0,1] , [3,9.0,1,1,15.2458,0,False,1,0,0] , [1,16.0,0,1,39.4,0,False,0,0,1] , [2,44.0,1,0,26.0,0,False,0,0,1] , [3,18.0,0,1,9.35,0,False,0,0,1] , [1,45.0,1,1,164.8667,0,False,0,0,1] , [1,51.0,0,0,26.55,1,False,0,0,1] , [3,24.0,0,3,19.2583,0,False,1,0,0] , [3,29.69911764705882,0,0,7.2292,1,True,1,0,0] , [3,41.0,2,0,14.1083,1,False,0,0,1] , [2,21.0,1,0,11.5,1,False,0,0,1] , [1,48.0,0,0,25.9292,0,False,0,0,1] , [3,29.69911764705882,8,2,69.55,0,True,0,0,1] , [2,24.0,0,0,13.0,1,False,0,0,1] , [2,42.0,0,0,13.0,0,False,0,0,1] , [2,27.0,1,0,13.8583,0,False,1,0,0] , [1,31.0,0,0,50.4958,1,False,0,0,1] , [3,29.69911764705882,0,0,9.5,1,True,0,0,1] , [3,4.0,1,1,11.1333,1,False,0,0,1] , [3,26.0,0,0,7.8958,1,False,0,0,1] , [1,47.0,1,1,52.5542,0,False,0,0,1] , [1,33.0,0,0,5.0,1,False,0,0,1] , [3,47.0,0,0,9.0,1,False,0,0,1] , [2,28.0,1,0,24.0,0,False,1,0,0] , [3,15.0,0,0,7.225,0,False,1,0,0] , [3,20.0,0,0,9.8458,1,False,0,0,1] , [3,19.0,0,0,7.8958,1,False,0,0,1] , [3,29.69911764705882,0,0,7.8958,1,True,0,0,1] , [1,56.0,0,1,83.1583,0,False,1,0,0] , [2,25.0,0,1,26.0,0,False,0,0,1] , [3,33.0,0,0,7.8958,1,False,0,0,1] , [3,22.0,0,0,10.5167,0,False,0,0,1] , [2,28.0,0,0,10.5,1,False,0,0,1] , [3,25.0,0,0,7.05,1,False,0,0,1] , [3,39.0,0,5,29.125,0,False,0,1,0] , [2,27.0,0,0,13.0,1,False,0,0,1] , [1,19.0,0,0,30.0,0,False,0,0,1] , [3,29.69911764705882,1,2,23.45,0,True,0,0,1] , [1,26.0,0,0,30.0,1,False,1,0,0] , [3,32.0,0,0,7.75,1,False,0,1,0]])
#print(type(pred_data))
predictors = df.drop(columns=['survived'], axis=1)
#target = df['wage_per_hour'].values
n_cols = predictors.shape[1]
# Convert the target to categorical: target
target = to_categorical(df.survived)
#print(target)
model = Sequential()
model.add(Dense(32, activation='relu', input_shape = (n_cols,)))
model.add(Dense(2, activation='softmax'))
model.compile(optimizer='sgd',
loss='categorical_crossentropy',
metrics=['accuracy'])
model.fit(predictors, target)
# Calculate predictions: predictions
predictions = model.predict(pred_data)
# Calculate predicted probability of survival: predicted_prob_true
predicted_prob_true = predictions[:,1]
# print predicted_prob_true
print(predicted_prob_true)
Changing optimization parameters¶
In [ ]:
def get_new_model():
model = Sequential()
model.add(Dense(100, activation='relu', input_shape = (n_cols,)))
model.add(Dense(100, activation='relu'))
model.add(Dense(2, activation='softmax'))
return(model)
In [ ]:
# Import the SGD optimizer
from keras.optimizers import SGD
# Create list of learning rates: lr_to_test
lr_to_test = [.000001, 0.01, 1]
# Loop over learning rates
for lr in lr_to_test:
print('nnTesting model with learning rate: %fn'%lr )
# Build new model to test, unaffected by previous models
model = get_new_model()
# Create SGD optimizer with specified learning rate: my_optimizer
my_optimizer = SGD(lr=lr)
# Compile the model
model.compile(optimizer=my_optimizer, loss='categorical_crossentropy')
# Fit the model
model.fit(predictors, target)
Model validation¶
In [ ]:
# Save the number of columns in predictors: n_cols
n_cols = predictors.shape[1]
input_shape = (n_cols,)
# Specify the model
model = Sequential()
model.add(Dense(100, activation='relu', input_shape = input_shape))
model.add(Dense(100, activation='relu'))
model.add(Dense(2, activation='softmax'))
# Compile the model
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])
# Fit the model
hist = model.fit(predictors, target, validation_split=.3)
Early stopping: Optimizing the optimization¶
In [ ]:
# Import EarlyStopping
from keras.callbacks import EarlyStopping
# Save the number of columns in predictors: n_cols
n_cols = predictors.shape[1]
input_shape = (n_cols,)
# Specify the model
model = Sequential()
model.add(Dense(100, activation='relu', input_shape = input_shape))
model.add(Dense(100, activation='relu'))
model.add(Dense(2, activation='softmax'))
# Compile the model
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])
# Define early_stopping_monitor
early_stopping_monitor = EarlyStopping(patience=2)
# Fit the model
model.fit(predictors, target, epochs=30, validation_split=.3, callbacks=[early_stopping_monitor])
Experimenting with wider networks¶
In [ ]:
# Define early_stopping_monitor
early_stopping_monitor = EarlyStopping(patience=2)
# Save the number of columns in predictors: n_cols
n_cols = predictors.shape[1]
input_shape = (n_cols,)
# Specify the model
model_1 = Sequential()
model_1.add(Dense(100, activation='relu', input_shape = input_shape))
model_1.add(Dense(100, activation='relu'))
model_1.add(Dense(2, activation='softmax'))
# Compile the model
model_1.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])
model_1.fit(predictors, target, epochs=30, validation_split=.3, callbacks=[early_stopping_monitor])
# Create the new model: model_2
model_2 = Sequential()
# Add the first and second layers
model_2.add(Dense(100, activation='relu', input_shape=input_shape))
model_2.add(Dense(100, activation='relu', input_shape=input_shape))
# Add the output layer
model_2.add(Dense(2, activation='softmax'))
# Compile model_2
model_2.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])
# Fit model_1
model_1_training = model_1.fit(predictors, target, epochs=15, validation_split=0.2, callbacks=[early_stopping_monitor], verbose=False)
# Fit model_2
model_2_training = model_2.fit(predictors, target, epochs=15, validation_split=0.2, callbacks=[early_stopping_monitor], verbose=False)
# Create the plot
plt.plot(model_1_training.history['val_loss'], 'r', model_2_training.history['val_loss'], 'b')
plt.xlabel('Epochs')
plt.ylabel('Validation score')
plt.show()
Adding layers to a network¶
In [ ]:
# The input shape to use in the first hidden layer
input_shape = (n_cols,)
# Create the new model: model_2
model_2 = Sequential()
# Add the first, second, and third hidden layers
model_2.add(Dense(50, activation='relu', input_shape=input_shape))
model_2.add(Dense(50, activation='relu'))
model_2.add(Dense(50, activation='relu'))
# Add the output layer
model_2.add(Dense(2, activation='softmax'))
# Compile model_2
model_2.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])
# Fit model 1
model_1_training = model_1.fit(predictors, target, epochs=20, validation_split=0.4, callbacks=[early_stopping_monitor], verbose=False)
# Fit model 2
model_2_training = model_2.fit(predictors, target, epochs=20, validation_split=0.4, callbacks=[early_stopping_monitor], verbose=False)
# Create the plot
plt.plot(model_1_training.history['val_loss'], 'r', model_2_training.history['val_loss'], 'b')
plt.xlabel('Epochs')
plt.ylabel('Validation score')
plt.show()
The model with the lower loss value is the better model
Building your own digit recognition model¶
In [ ]:
# Import necessary modules
import pandas as pd
import keras
from keras.layers import Dense
from keras.models import Sequential
from keras.utils import to_categorical
df = pd.read_csv('../input/mnist-data/mnist.csv')
print(df.head())
X = df.drop(df.columns[0], axis=1).values
# Convert the target to categorical: target
y = to_categorical(df.iloc[:,0].values)
print(X.shape)
print(y.shape)
#n_cols = predictors.shape[1]
#target = to_categorical(df.survived)
# Create the model: model
model = Sequential()
# Add the first hidden layer
model.add(Dense(50, activation='relu', input_shape=(X[0].shape[0],)))
# Add the second hidden layer
model.add(Dense(50, activation='relu'))
# Add the output layer
model.add(Dense(10, activation='softmax'))
# Compile the model
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])
# Fit the model
model.fit(X, y, validation_split=.3)
You should see better than 90% accuracy recognizing handwritten digits, even while using a small training set of only 1750 images!
Categories